document A, B가 있을 때, 2가지가 얼마나 비슷한지를 나타내는 척도이다.
1) Jaccard Similarity (자카드 유사도)
2) Cosine Similarity (코사인 유사도)
3) Euclidean Distance (유클리디안 거리)
Sentence 1: AI is our friend and it has been friendly
Sentence 2: AI and humans have always been friendly

1) Jaccard Similarity :
document A와 B가 있다고 했을 때, 각각의 document의 word set이 겹치는 정도에 따라 두 document간 유사도가 높다고 판단한다. 값은 0과 1사이의 값이다.


2) Cosine Similarity :
document A와 B를 tf_idf, bag-of-words, counts, freq 등을 통해 벡터화해서 표현한 후, vector_A와 vector_B의 cosine값을 이용해서 두 document가 얼마나 비슷한지 평가하는데 사용한다.
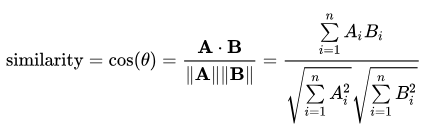
cos 값은 같은 방향일 경우 그 값이 크고 반대 반향일 경우 값이 작아진다. 즉 두 벡터의 방향이 평행할 수록 document도 더 비슷할 것이다.

길이가 2인 벡터로 단순히 생각하면 a = (1, 1), b = (0,1, 0,1) 또한 similarity 1로 유사도가 매우 크게 평가 될 수 있어서 잘 안 와 닿을 수 있다. (사실은 이런일이 생기지 않게 적절히 normalisation을 거친다.) 하지만 cosine similarity는 euclidean distance와는 다른 개념이기에 거리가 아닌 방향 일 뿐더러, vector의 길이가 매우 길다면 위와 같이 방향이 같은 케이스도 매우 드물다는 것을 알 수 있을 것이다.

Cosine Similarity = (0.302*0.378) + (0.603*0.378) + (0.302*0.378) + (0.302*0.378) + (0.302*0.378) = 0.684
3) Euclidean distance :
document A와 B를 tf_idf, bag-of-words, counts, freq 등을 통해 벡터화해서 표현한 후, vector_A와 vector_B의 직선거리를 이용해서 두 document가 얼마나 비슷한지 평가하는데 사용한다.
http://joonable.tistory.com/14
[참고]
https://towardsdatascience.com/overview-of-text-similarity-metrics-3397c4601f50
http://blog.christianperone.com/2013/09/machine-learning-cosine-similarity-for-vector-space-models-part-iii/
https://ko.wikipedia.org/wiki/%EC%BD%94%EC%82%AC%EC%9D%B8_%EC%9C%A0%EC%82%AC%EB%8F%84
'Data Science > NLP' 카테고리의 다른 글
| 텍스트 전처리 과정과 사전의 쓰임 (0) | 2019.04.05 |
|---|---|
| Bag-Of-Words Model (0) | 2018.11.25 |
| Text Preprocessing (텍스트 전처리) (0) | 2018.11.25 |
| NLP 기본 가정 (0) | 2018.11.25 |