검색엔진
- ES는 기본적으로검색엔진이다.
- 기본 DB와 가장 다른점은 쿼리이후 결과값이(document = row)마다 쿼리의 조건문과 얼마나 적합한지를 나타내는 score를 얻을 수 있다.
- 즉 단순히 조건절에 의해 True(1)/False(0)에 해당하는 결과값만 취하는게 아니라 각 결과값마다 유사한 정도(relevance score, 0.9 / 0.2)를 뽑아낼 수 있다.
- 참고 : 검색엔진은 주로 텍스트를 많이 담고 있어서 “검색어“가 document와 비슷한지 보여주는 것은 매우 중요한 ㅣㄹ이다.
|
(참고) 분산 저장 및 처리 방식 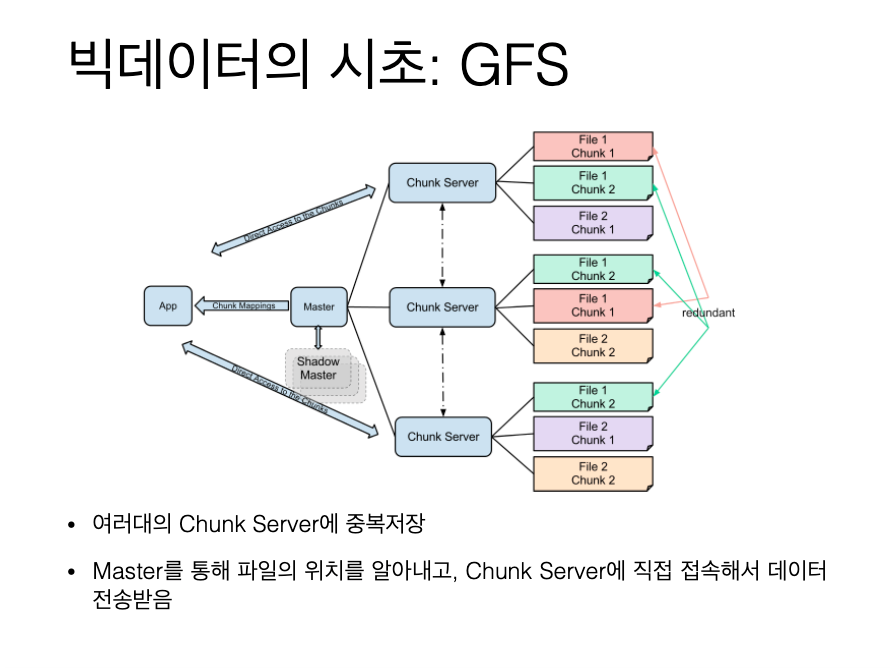 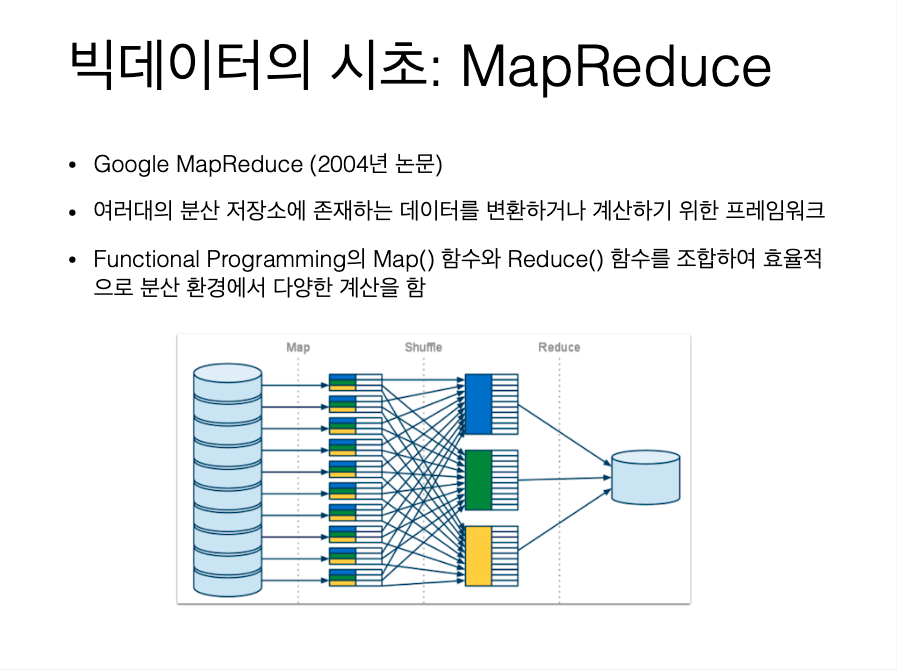  |
score vs. filter
- query를 날리다 보면 score를 항상 필요로 하지 않는 경우도 존재한다.
- score는 필요하지 않고 filter만 필요한 경우 :고객의 성별과 연령대(filter)를 가져오는 경우
- score와 filter가 동시에 필요한 경우 :고객의 성별과 연령대가 선호하는 아이템 중(filter)에서가장 적합한 상품(score)을 가져오는 경우
- 참고 : 또한, score를 요구하는 연산은 기본적으로 complexity가 높고, 캐싱을 지원하지 않는다. 그렇기 때문에 하나의 query 상에서 query와 filter를 적절히 나눠서 뽑는게 중요하다.
- 이 부분이 굉장히 헷갈리는데 보통score를 뽑는 부분을 query 부분이라고 하고filter를 뽑는 부분을 filter 부분이라고 한다. es query안에 query부분, filter부분이 존재한다고 생각하면 된다.
-
GET ai_centre/_search { "query": { # query 부분 (여기에 쓰는 조건문은 score에 반영된다) "bool": { "filter": { # filter 부분 (여기에 쓰는 조건문은 score에 반영되지 않는다. but 빠름) } } } }
-
score
- score는 쿼리 내 필드에 부여된 조건과 도큐먼트 내 필드값이 얼마나 유사한지 score 나타내고, 각 필드 score의 곱 또는 합으로 document의 score가 결정된다.
- 참고:
- categorical 데이터 (단순 키워드 포함)는 bm25(tf_idf 라고 생각하면 됨)로 나타내고 있다.
- numeric 데이터는 0, 1로 표현된다.
- scrpit_score : 사용자에 목적에 맞게 산출식을 script(painless)로 표현할 수 있고 왠만하면 다되는것 같긴한데.. 코드가 복잡해진다. 하지만 이것만 잘 쓰면 단순한 리랭킹도 가능하다.
역색인
- 검색엔진이 빠른 이유는 역색인을 지원하기 때문이다.
- value가 있는 위치(doc_id or pk)를 보관하는 형태 생각하면 된다.
- https://www.geeksforgeeks.org/inverted-index/
NoSQL
- ES는 NoSQL 데이터라서 비정형 형태의 데이터를 저장한다.
- 안되는것:
- JOIN을 지원하지 않는다. JOIN 쿼리가 있으면 나눠서 2번 날려야한다.
- WHERE 절에 IN 쿼리도 안된다는 소문이 있던데 한번더 확인필요
- case문 + 쿼리 중 파생변수 생성 안된다. (참고 : script를 쿼리중에 쓰면 가능하다. 또한, scripted fields라고 있긴한데 시각화하는데서 주로 사용하는 것 같아서 사용하지 말라고 되어있다.)
용어차이
ES**SQL**
|
field |
column |
|
document |
row |
|
index |
table |
|
type(deprecated) |
table |
|
mapping |
schema |
|
_id |
pk |
ELK stack
- E(elasticsearch) : 검색엔진
- L(logstash) : ETL (참고 : 꼭 es 데이터만 etl 할 수 있는게 아님)
- K(kibana) : console +GUI setting + 시각화
ES기능 이용하기 (es rest api)
- 기본적으로 es를 setting하거나 데이터를 es에 CRUD하는 동작 모두 ES REST api를 이용한다.
- API에 주로 json 형태로 명령문을 만들어서 보내고 json 형태로 데이터를 받는다. (위의 query문 참조)
- ai_centre에서 unit이 tf2인 docs를 보고싶을때 명령어를 보내는 명령어는 다음과 같다.
- LINUX(curl 명령어)
curl -XGET "http://elassandra-elasticsearch:9200/ai_centre/_search" \ -H 'Content-Type: application/json' \ -d' { "query": { "term": { "unit": "tf2" } } }' - 저걸 shell 상에서 json 형태로 만드는건 너무 힘들다.
- KIBANA(console 상에서 실행)
-
GET ai_centre/_search { "query": { "term": { "unit": "tf2" } } }
- LINUX(curl 명령어)
- 참고 : python에 elasticsearch라는 패키지를 통해 es에 접속하여 수행할 수 있는데 내부적으로는 모두 curl 기반의 api 호출로 이루어진다.
data type
https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-types.html
'IT > Elasticsearch' 카테고리의 다른 글
| Elastic Search DSL search query 기초 (0) | 2021.04.19 |
|---|---|
| nori pos tag summary (0) | 2019.02.09 |
| Elastic Search analyse process (analyser + tokeniser + tokenfilter) (0) | 2019.02.09 |
| logstash error - unrecognized SSL message (0) | 2018.11.12 |
| nori, arirang, openkoreantext, mecab 형태소분석기 사전형식 (0) | 2018.11.08 |