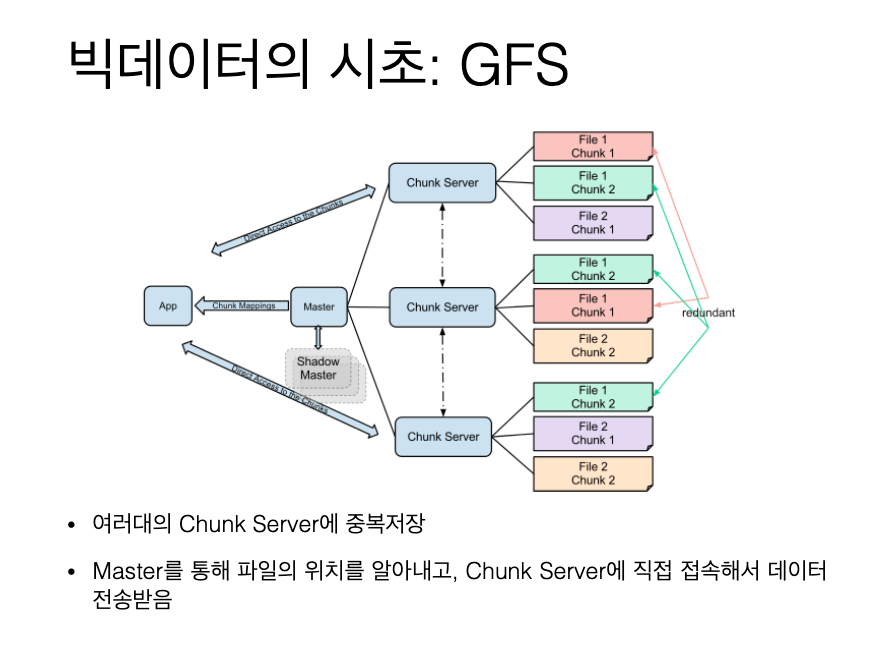
검색엔진 ES는 기본적으로검색엔진이다. 기본 DB와 가장 다른점은 쿼리이후 결과값이(document = row)마다 쿼리의 조건문과 얼마나 적합한지를 나타내는 score를 얻을 수 있다. 즉 단순히 조건절에 의해 True(1)/False(0)에 해당하는 결과값만 취하는게 아니라 각 결과값마다 유사한 정도(relevance score, 0.9 / 0.2)를 뽑아낼 수 있다. 참고 : 검색엔진은 주로 텍스트를 많이 담고 있어서 “검색어“가 document와 비슷한지 보여주는 것은 매우 중요한 ㅣㄹ이다. (참고) 분산 저장 및 처리 방식 score vs. filter query를 날리다 보면 score를 항상 필요로 하지 않는 경우도 존재한다. score는 필요하지 않고 filter만 필요한 경우 :고객의 성..